Process-Based Therapy & Idionomic Analysis
Personalized psychology for lasting change.
Process-based therapy (PBT) is an approach to mental health care that targets the core psychological processes driving a person's difficulties — such as attention, cognition, emotion regulation, and motivation — rather than treating a diagnostic label with a fixed protocol. Idionomic analysis is a key method: it studies each individual's own patterns first, and generalizes to group-level findings only when they improve the fit for that person.
Idionomic Analysis / Process-Based Therapy (PBT) represents the forefront of personalized clinical psychology. This approach combines deep individual insight with the power of evidence-based strategies. Rather than relying on diagnostic labels alone, idionomic analysis maps the unique patterns of a person's thoughts, emotions, behaviors, and biology — capturing how they dynamically interact over time.
Paired with PBT, the framework pinpoints core psychological processes: cognitive flexibility, emotional regulation, attention, motivation. The result is targeted interventions tailored to the person, not the disorder. Whether you're a clinician, researcher, or client, this precision-based model supports more effective, meaningful mental health care.
Jump to

The key is to start with the individual (idiographic) and then only move to group-level (nomothetic) generalisations when appropriate. Idio-graphic + nom-ethetic = Idionomic.
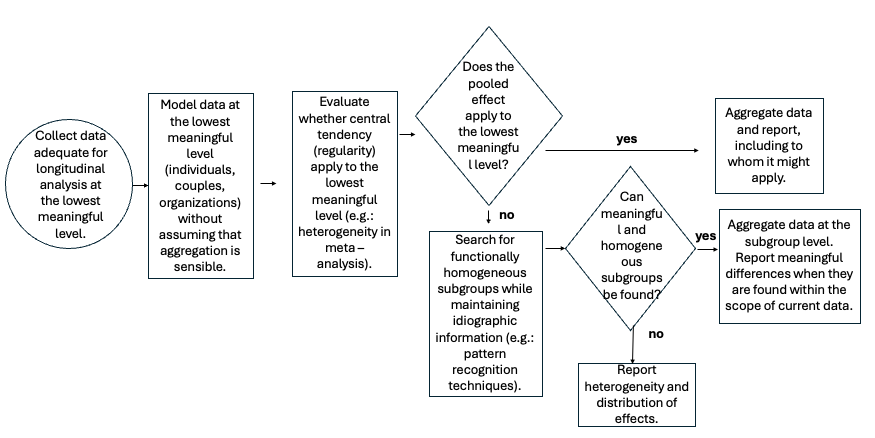
- Collect sufficient data at the lowest meaningful level.
- This is Level 1 — individual participants, couples, families, or countries.
- May involve intensive longitudinal data to capture meaningful within-unit patterns.
- Build a model for each Level 1 unit.
- For example, use a simple ARIMA model for each individual to estimate the link between a process (X) and an outcome (Y).
- Evaluate whether aggregation is appropriate.
- Use techniques like meta-analysis to assess the pooled effect size and the heterogeneity (e.g., I²).
- Aggregate if appropriate. If the pooled effect accurately represents most individual data.
- Explore functional subgroups if heterogeneity is high. Look for functionally homogeneous subgroups.


The idionomics R package brings idionomic analysis into one place. If you have data where the same people are measured many times (a daily diary, an experience-sampling study, weekly therapy ratings, repeated couple interactions), this package lets you analyse them person-by-person first, and then ask whether it's safe to combine those individual stories into a group average. The traditional approach does the opposite: it averages first and assumes everyone is alike. That assumption hides a lot.
The package is now on CRAN, so installing it takes one line:
Once it's loaded, the main functions you'll reach for are:
i_screener()— flags participants whose responses look like careless or random clicking, so you can decide who to keep before modelling.pmstandardize()— rescales each variable within each person, so a "high" score for one person isn't compared to a "high" score for another. This is the standard first step before any within-person analysis.i_detrender()— removes long-term linear trends from each person's time series, so you can study day-to-day fluctuations cleanly without slow drift confounding the results.iarimax()— fits a per-person time-series model linking a predictor to an outcome, then meta-analyses across people. This is the workhorse: out comes both each person's individual effect and the group summary, with a measure of how variable the effect is.i_pval()— computes individual p-values, so you can see which specific participants showed a reliable effect.sden_test()— tests for the "equisyncratic null" pattern, where the group mean is near zero but only because half the people show a positive effect and the other half show a negative one. This is the test that catches the cases where averaging genuinely hides a story.looping_machine()— identifies feedback loops in person-specific networks (e.g., A drives B drives C drives A), which is useful for case formulation.
A worked vignette walks through the full pipeline with example data: see the idionomics Pipeline vignette on the CRAN page below.


Authors: Cristóbal Hernández (creator and maintainer), Joseph Ciarrochi, Steven Hayes, Baljinder Sahdra. Methods are described in Hernández et al. (2024), Ciarrochi et al. (2024), and Sahdra et al. (2024) — all of which are downloadable in the article library below.
Type any word (author, title, year, topic) to filter. Click a tag to narrow by topic. Click a title to read the PDF in a new tab, or click Download PDF to save it to your computer.
Frequently Asked Questions
What is process-based therapy (PBT)?
Process-based therapy (PBT) targets the core biopsychosocial processes of change that produce and maintain a person's difficulties — across cognition, affect, attention, sense of self, motivation, and overt behavior — rather than matching a diagnostic label to a standardized protocol. It asks which processes are driving this individual's problem and how to shift them, with the practical goal of predicting and influencing that person's behavior with precision, scope, and depth.
What is idionomic analysis?
“Idionomic” combines idiographic (the individual) and nomothetic (the general). An idionomic analysis begins with the individual — modeling each person's own processes as they change over time — and builds toward general principles only when those generalizations still hold for the individuals they describe. It inverts the usual order of psychological science: rather than deriving a group law and assuming it fits everyone, it establishes what is true for people one at a time, then asks how far that generalizes.
Why doesn't the group average describe the individual?
Because averaging across people hides the individual — and doing within-person analysis doesn't rescue you if you still average across people. For a group finding to describe a person, the process has to be ergodic: the same relationship must hold for everyone (homogeneity) and stay stable within a person over time (stationarity). Psychological processes usually fail these conditions. A between-person average — relating variables across people — can describe no one: the relationship may be weaker, absent, or even reversed within a given individual. But the same holds for an average within-person relationship: even when you correctly measure how each person's variables move together over time, averaging those within-person patterns across a group can still fit no single person, because individuals differ in their own dynamics. This is why an idionomic approach models each person's processes first, and generalizes to a group only when that generalization actually fits the individuals it is meant to describe.
What's the difference between nomothetic and idiographic approaches?
Nomothetic research looks for general laws that apply across people, using group averages and standardized effects. Idiographic research studies the individual's own dynamics over time. Idionomic work integrates the two, but treats the individual level as primary and requires group generalizations to earn their place by improving individual fit.
What is the Extended Evolutionary Meta-Model (EEMM)?
The EEMM organizes the processes of change into a common language. It treats healthy change as a matter of variation, selection, and retention — the core logic of evolution — operating across six psychological dimensions (cognition, affect, attention, sense of self, motivation, overt behavior) and three levels (biophysiological, psychological, sociocultural). This lets clinicians locate any change process in a shared map instead of arguing across rival schools with separate vocabularies.
How is PBT different from the DSM protocol-for-syndrome model?
The “protocol-for-syndrome” model assumes that people who share a diagnosis share the same underlying problem, and so should receive the same standardized protocol. PBT questions each assumption: diagnostic categories are internally heterogeneous, the same symptom can arise from different processes in different people, and group-level evidence does not guarantee benefit for a given individual. PBT instead targets the change processes actually operating in this person's life.